Opmerkingen over ‘Chatcontrole’
Oorspronkelijke publicatie: Remarks on ‘Chat Control’
Auteur: Matthew Green
Publicatie: A Few Thoughts on Cryptographic Engineering
Datum: 23 maart 2023
Hier de vertaling in het Nederlands.
| Kernbegrippen | |
|---|---|
| Eind-tot-eind-versleuteling | Het toepassen van versleuteling (encryptie) op berichten, zodat alleen de verzender en de ontvanger van het bericht dit in ontcijferde vorm kunnen lezen. Niemand anders dan de verzender en de ontvanger heeft toegang tot de onversleutelde inhoud van het bericht, zelfs de berichtendienst die het verstuurt niet. |
| Scannen aan cliëntzijde | Het gebruik van systemen die de inhoud van een bericht (zoals tekst, afbeeldingen, video’s, of andere bestanden) op het apparaat van de afzender scannen om te zien of het overeenkomt met gegevens in een database, nog voordat het bericht naar de beoogde ontvanger wordt verzonden. |
| Scannen aan serverzijde | Het gebruik van systemen die de inhoud van een bericht (zoals tekst, afbeeldingen, video’s, of andere bestanden) op een centrale server scannen. |
| Hash | Een codering van gegevens naar een waarde van een kleine, vaste omvang. Een soort digitale vingerafdruk. Wordt gebruikt in het versleutelen van gegevens. |
| Cliënt | Een apparaat (bijvoorbeeld een laptop, tablet, of telefoon) dat informatie en toepassingen van een server kan ontvangen. |
| Server | Een computer of computerprogramma dat de toegang tot een gecentraliseerde bron of dienst in een netwerk beheert. |
Op 23 maart werd ik uitgenodigd om deel te nemen aan een paneldiscussie bij de Europese Associatie van Internetdienstenaanbieders (EuroISPA). De focus van deze discussie lag op recente wetgevingsvoorstellen, met name het nieuwe ‘chatcontrole’ voorstel van de Europese Commissie voor het scannen van berichteninhoud, evenals de toekomst van versleuteling en grondrechten. Dit zijn de inleidende opmerkingen die ik had voorbereid.
Bedankt dat u me vandaag heeft uitgenodigd.
Ik zou moeten beginnen met een korte introductie. Ik ben hoogleraar informatica en onderzoeker op het gebied van toegepaste cryptografie. Dagelijks houdt dit in dat ik mijn werk zicht richt op het ontwerpen van versleutelsystemen. Het meeste van wat ik doe, bestaat uit het bouwen van dingen: ik ontwerp nieuwe versleutelsystemen en probeer bestaande versleuteltechnologieën nuttiger te maken.
Soms breken ik en mijn collega’s ook versleutelsystemen. Ik zou willen dat ik u kon vertellen dat dit niet vaak gebeurt, maar het gebeurt veel vaker dan je zou denken, en vaak in systemen met miljarden gebruikers die bovendien heel moeilijk te repareren zijn. Versleuteling is een erg opwindend gebied om in te werken, maar het is ook een jong gebied. We kennen niet alle manieren waarop we dingen fout kunnen hebben, en we leren nog steeds.
Ik ben hier vandaag om alle vragen over versleuteling in online communicatiesystemen te beantwoorden. Maar ik ben hier vooral omdat de Europese Commissie een voorstel heeft ingediend dat mij grote zorgen baart. Dit voorstel, dat in de volksmond ‘chatcontrole’ wordt genoemd, zou vereisen dat technologie voor het scannen van berichteninhoud wordt toegevoegd aan programma’s voor het versturen van privéberichten. Dit voorstel is op technisch niveau niet goed geanalyseerd, en ik maak me grote zorgen dat de EU het in wetgeving zou kunnen gaan omzetten.
Voordat ik op die technische details inga, wil ik eerst ingaan op de vraag waar versleuteling in deze discussie past.
Sommigen hebben betoogd dat het nieuwe voorstel helemaal niet over versleuteling gaat. Op een bepaald niveau hebben deze mensen gelijk. De nieuwe wetgeving gaat fundamenteel over privacy en vertrouwelijkheid, en waar de belangen van handhaving tegen deze zaken moeten worden afgewogen. Ik heb hier een mening over, maar ik ben geen EU-burger. Helaas is dit een beladen debat dat de Europeanen onder elkaar zullen moeten voeren. Ik benijd u niet.
Wat mij zorgen baart, is dat de Commissie geen goed idee lijkt te hebben van de technische implicaties van hun voorstel, en niet lijkt te hebben overwogen hoe het voorstel de veiligheid van onze wereldwijde communicatiesystemen zal schaden. En dit heeft gevolgen voor mij, omdat de beveiliging van onze communicatie-infrastructuur niet gelokaliseerd op een bepaald continent: als de 447 miljoen burgers van de EU stemmen om deze technische systemen te verzwakken, kan dit gevolgen hebben voor alle gebruikers van computerbeveiligingstechnologie wereldwijd.
Dus waarom is versleuteling zo cruciaal voor dit debat?
Versleuteling is belangrijk omdat dit het beste gereedschap is dat we hebben voor het beveiligen van privégegevens. Mijn tijd hier is beperkt, maar als ik dacht dat ik al mijn tijd zou moeten gebruiken om u van dit ene feit te overtuigen, dan zou ik dat doen. Letterlijk elke andere benadering die we ooit hebben gebruikt om waardevolle gegevens te beschermen, is gecompromitteerd, en vaak ook behoorlijk ernstig. En omdat versleuteling het enige gereedschap is dat voor dit doel werkt, moet elk systeem dat voorstelt om privégegevens te scannen – als een puur technische vereiste – worstelen met de technische gevolgen die het met zich meebrengt wanneer die gegevens worden beschermd met eind-tot-eind-versleuteling.
En die technische gevolgen zijn aanzienlijk. Ik heb de door de Commissie opgestelde Effectbeoordeling gelezen, en ik hoop dat ik niet onbeleefd ben tegen dit publiek als ik zeg dat ik die zeer naïef en alarmerend vond. Mijn indruk is dat de auteurs, op puur technisch niveau, niet begrijpen dat ze technologieleveranciers vragen om systemen in te zetten waarvan geen van hen weet hoe ze deze veilig moeten bouwen. Evenmin heeft de Commissie mensen met de technische en wetenschappelijke expertise geraadpleegd die nodig zouden zijn om dit voorstel levensvatbaar te maken.
Om mijn bezorgdheid uit te leggen, moet ik kort wat achtergrondinformatie geven over hoe systemen voor het scannen van berichteninhoud werken: zowel historisch, als in de context die de EU voorstelt.
Moderne systemen voor het scannen van inhoud zijn een nieuwe creatie. Ze zijn pas sinds ongeveer 2009 in gebruik, en worden pas sinds rond 2011 op grote schaal ingezet. Deze systemen evalueren normaal gesproken berichten die naar een server zijn geüpload, vaak een sociaal netwerk of een openbare opslagplaats. In historische systemen — dat wil zeggen, oudere systemen zonder eind-tot-eind-versleuteling — verwerkten ze niet-versleutelde gegevens in platte tekst gegevens, meestal om te zoeken naar bekende mediabestanden met kindermisbruikmateriaal. Na het vinden van een dergelijke afbeelding, voeren ze verschillende rapporteer-taken uit: meestal sturen ze een notificatie naar werknemers bij de aanbieder, die de zaak vervolgens kunnen escaleren naar de politie.
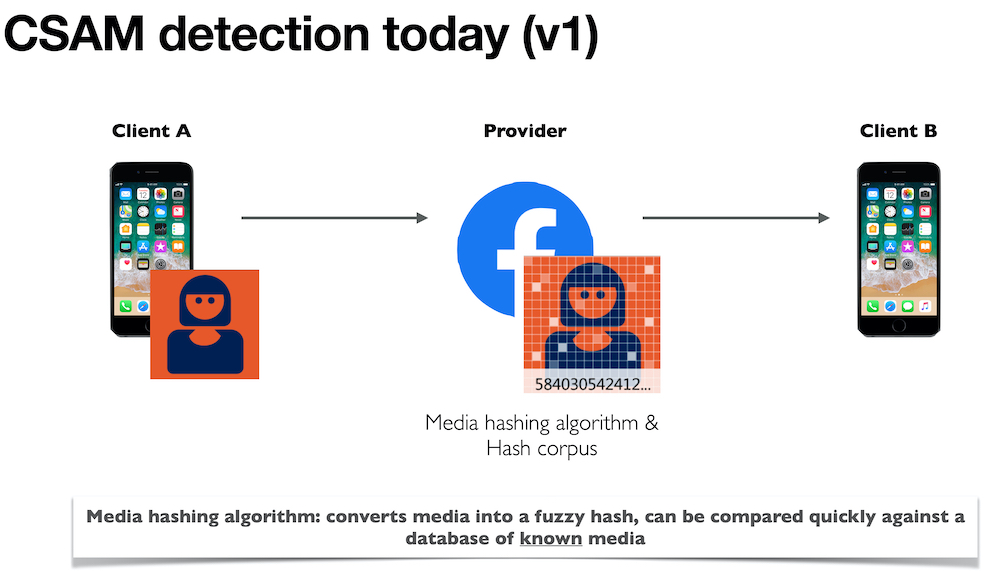 Kindermisbruikmateriaal-detectie vandaag (versie 1)
Kindermisbruikmateriaal-detectie vandaag (versie 1)
Historische scansystemen, zoals Microsoft’s PhotoDNA, gebruikten een perceptueel hash-algoritme om elke afbeelding terug te brengen tot een ‘vingerafdruk’ die kan worden vergeleken met een database met bekende illegale inhoud. Deze databases worden onderhouden door kinderveiligheidsorganisaties zoals het NCMEC. De hash-algoritmen zelf zijn met opzet onvolmaakt: ze zijn ontworpen om vergelijkbare vingerafdrukken te produceren voor bestanden die (voor het menselijk oog) identiek lijken, zelfs als een gebruiker de gegevens van het bestand enigszins heeft gewijzigd.
Een eerste beperking van deze systemen is dat hun onnauwkeurigheid kan worden uitgebuit. Het is relatief makkelijk om, met behulp van pas ontwikkelde technieken, nieuwe afbeeldingen te maken die onschuldige, legale mediabestanden lijken te zijn, maar die een vingerafdruk opleveren die identiek is aan schadelijk, illegaal kindermisbruikmateriaal.
Een tweede beperking van deze op een hash gebaseerde systemen is dat ze geen nieuw kindermisbruikmateriaal kunnen ontdekken. Dit betekent dat criminelen die nieuw gemaakte misbruikmedia plaatsen, in feite onzichtbaar zijn voor deze scanners. Zelfs tien jaar geleden zou de taak van het vinden van nieuw kindermisbruikmateriaal menselijke werkers nodig hebben gehadt. Recente ontwikkelingen in kunstmatige intelligentie hebben het echter mogelijk gemaakt om diepe neurale netwerken op dergelijke beelden te trainen, zodat deze netwerken kunnen proberen nieuwe voorbeelden ervan te ontdekken:
 Kindermisbruikmateriaal-detectie vandaag (versie 2)
Kindermisbruikmateriaal-detectie vandaag (versie 2)
Uiteraard is het sleutelwoord in elk op een machine gebaseerd beeldherkenningssysteem ‘proberen’. Alle beeldherkenningssystemen zijn enigszins feilbaar (zie voorbeeld rechts) en zelfs wanner ze goed werken, maken ze vaak geen onderscheid tussen legale en illegale inhoud. Bovendien kunnen deze systemen worden uitgebuit door kwaadwillende gebruikers om verrassende resultaten te produceren. Ik kom daar zo op terug.
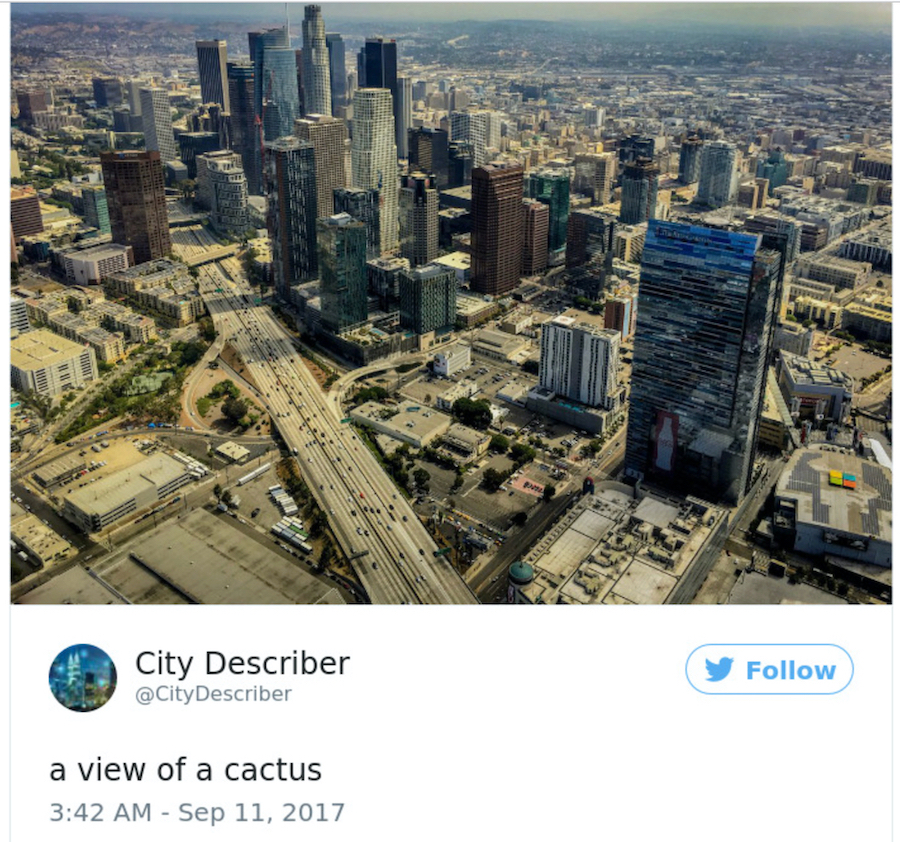 De stadsbeschrijver op Twitter omschrijft een stadsgezicht als ‘uitzicht op een kaktus’
De stadsbeschrijver op Twitter omschrijft een stadsgezicht als ‘uitzicht op een kaktus’
Maar sta me toe terug te keren naar de belangrijkste uitdaging: deze systemen integreren met versleutelde communicatiesystemen.
In eind-tot-eind versleutelde systemen, zoals WhatsApp of Apple iMessage of Signal, is scannen aan de serverzijde niet langer haalbaar. Het probleem hier is dat privégegevens versleuteld zijn wanneer ze de server bereiken en niet kunnen worden gescand. Het voorstel van de Commissie is niet specifiek over hoe met deze systemen moet worden omgegaan, maar het geeft aan dat dit scannen op het apparaat van de gebruiker moet worden gedaan voordat de inhoud wordt gecodeerd. Deze aanpak wordt scannen aan de cliëntzijde genoemd.
Er zijn hier verschillende uitdagingen.
Ten eerste, vormt scannen aan de cliëntzijde een uitzondering op de privacy-garanties van versleutelde systemen. In een standaard eind-tot-eind versleuteld systeem zijn uw gegevens privé voor u en de beoogde ontvanger. In een systeem met scannen aan de cliëntzijde zijn uw gegevens vertrouwelijk… met een asterisk. Dat wil zeggen, de gegevens zelf zijn privé, tenzij het scansysteem vaststelt dat er een overtreding heeft plaatsgevonden, waarna uw vertrouwelijkheid (stilletjes) wordt ingetrokken en niet-versleutelde gegevens worden verzonden naar de aanbieder (en dus naar iedereen die uw provider heeft gecompromitteerd).
Deze mogelijkheid om codering selectief uit te schakelen, creëert nieuwe kansen voor aanvallen. Als een aanvaller de omstandigheden kan identificeren waardoor het model de vertrouwelijkheid van uw versleuteling vermindert, kan ze nieuwe — en ogenschijnlijk onschadelijke — inhoud genereren die ervoor zorgt dat dit gaat gebeuren. Dit zal het scansysteem zeer snel overweldigen, waardoor het onbruikbaar wordt. Maar het zal ook de privacy van veel gebruikers ernstig aantasten.
Er bestaat ook een spiegelversie van deze aanvaller: zij zal kennis van het model gebruiken om deze systemen te omzeilen en nieuwe beelden en inhoud produceren die onveranderd lijken, maar die deze systemen helemaal niet kunnen ontdekken. De meest geavanceerde criminelen — hoogstwaarschijnlijk degenen die deze vreselijke inhoud in de eerste plaats hebben gemaakt — zullen zich in het volle zicht verbergen.
Ten slotte bestaat er een nog alarmerendere mogelijkheid: veel neurale netwerkclassificaties maken het mogelijk om de afbeeldingen te onttrekken die werden gebruikt om het model te trainen. Dit betekent dat elk complex neuraal netwerkmodel mogelijk afbeeldingen van misbruikslachtoffers bevat, welke aan verdere schade zouden worden blootgesteld als deze modellen zouden worden onthuld.
De enige bekende verdediging tegen al deze aanvallen is om de modellen zelf goed te beschermen: dat wil zeggen, om ervoor te zorgen dat de complexe systemen van neurale netwerkgewichten en/of hash-vingerafdrukken nooit worden onthuld. Historische systemen aan de serverzijde doen er alles aan om deze gegevens te beschermen, waarbij zelfs hun algoritmen vertrouwelijk worden gemaakt. Dit was mogelijk in systemen die scannen aan de serverzijde, omdat de gegevens alleen op een gecentraliseerde server staan. Het werkt niet goed met scannen aan de cliëntzijde, waarbij modellen naar de telefoons van gebruikers moeten worden gedistribueerd. En dus kunnen zonder een ander technisch ingrediënt modellen niet op de server of op het apparaat van de gebruiker bestaan.
Het enige serieuze voorstel dat heeft geprobeerd om deze technische uitdaging aan te pakken, werd bedacht — en vervolgens verlaten — door Apple in 2021. Dat voorstel was alleen gericht op het ontdekken van bekende inhoud met behulp van een perceptuele hash-functie. Het bedrijf stelde voor om geavanceerde cryptografie te gebruiken om de evaluatie van hash-vergelijkingen te “splitsen” tussen het apparaat van de gebruiker en de servers van Apple: dit zorgde ervoor dat het apparaat nooit een leesbare kopie van de hash-database ontving.
Het voorstel van Apple is om een aantal redenen mislukt, maar de technische mislukkingen hebben belangrijke lessen opgeleverd die door de Commissie grotendeels zijn genegeerd. Hoewel het systeem van Apple de hash-database beschermde, beschermde het niet de code van de op gepatenteerde neurale netwerken gebaseerde hash-functie die Apple had bedacht. Binnen twee weken na de openbare aankondiging konden gebruikers deze code ontfutselen en zowel de botsingsaanvallen als de ontwijkingsaanvallen die ik hierboven noemde opzetten.
 Een van de eerste ‘betekenisvolle’ botsingen tegen NeuralHash, gevonden door Gregory Maxwell.
Een van de eerste ‘betekenisvolle’ botsingen tegen NeuralHash, gevonden door Gregory Maxwell.
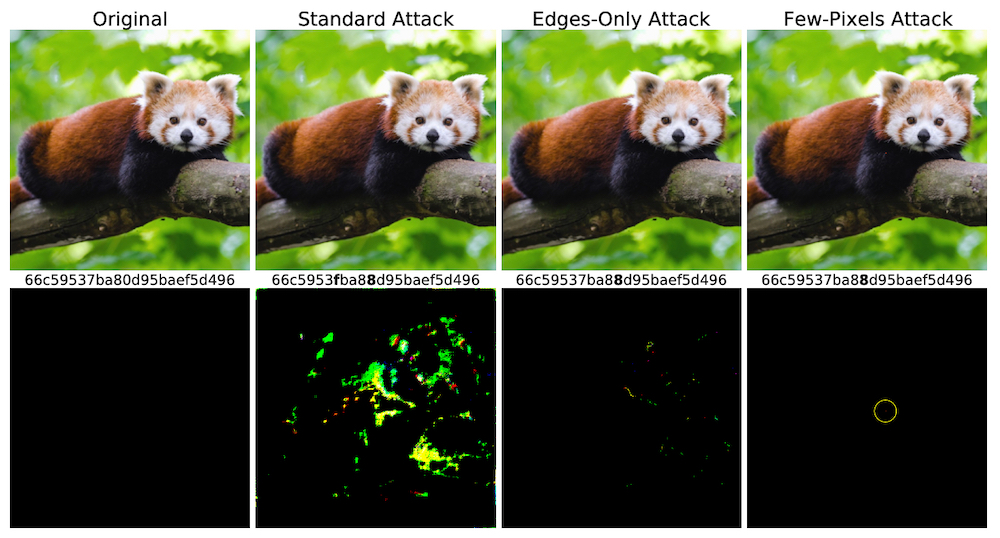 Ontduikingsaanvallen tegen Apple’s NeuralHash, van Struppek et al. (bron).
Ontduikingsaanvallen tegen Apple’s NeuralHash, van Struppek et al. (bron).
In de Commissie’s Effectbeoordeling wordt de Apple-aanpak als een succes beschouwd en wordt deze mislukking niet behandeld. Ik verzeker u dat dit niet is hoe dit werk van Apple wordt beschouwd binnen de technische gemeenschap, en waarschijnlijk ook niet binnen Apple zelf. Een van de meest capabele technologiebedrijven ter wereld wierp al hun kennis op dit probleem en werd door een groep hackers te schande gemaakt: eigenlijk nog voordat de inkt op hun voorstel droog was.
Dit falen is belangrijk omdat het de grenzen van onze mogelijkheden illustreert: op dit moment hebben we geen efficiënte manier om complexe neurale netwerken te evalueren op een manier die ons in staat stelt om ze geheim te houden. En dus is modelextractie een reële mogelijkheid in alle voorgestelde client-side scansystemen vandaag de dag. Bovendien, zoals mijn collega’s en ik hebben aangetoond, zijn zelfs ‘traditionele’ perceptuele hash-functies zoals Microsoft’s PhotoDNA kwetsbaar voor botsings- en ontwijkingsaanvallen, zodra hun code beschikbaar komt. Deze aanvallen zullen zich vermenigvuldigen, al was het maar omdat 4chan bestaat: en omdat sommige mensen op internet niets liever doen dan andere internetgebruikers pijn doen.

Van Prokos et al. (bron)
 Dit voorbeeld laat zien hoe een hash-functie op basis van een neuraal netwerk (NeuralHash) kan worden misleid door onwaarneembare wijzigingen in een afbeelding aan te brengen.
Dit voorbeeld laat zien hoe een hash-functie op basis van een neuraal netwerk (NeuralHash) kan worden misleid door onwaarneembare wijzigingen in een afbeelding aan te brengen.
In de praktijk nodigt het voorstel van de Commissie – als het zou worden ingevoerd in productiesystemen – uit tot een reeks technische aanvallen die we vandaag de dag eenvoudigweg niet begrijpen, en waarover wetenschappers nog maar nauwelijks zijn begonnen na te denken. Bovendien is de Commissie er niet tevreden mee om zichzelf te beperken tot het scannen op bekende kindermisbruik-inhoud, zoals Apple deed. Hun wens om zich daar bovenop ook te richten op voorheen onbekende inhoud en tekstuele inhoud zoals ‘kinderlokkerij’, brengt van veel partijen risico’s met zich mee en vereist tegenmaatregelen tegen misbruik en toezicht die op dit moment volledig onderontwikkeld zijn.
Erger nog: de vereiste van het vaststellen dan ‘kinderlokkerij’ houdt in dat niet-geteste, en misschien zelfs ook nog-niet-eens-ontwikkelde AI-taalmodellen een kernonderdeel zullen zijn van de beveiligingssystemen van morgen. Dit is zorgwekkend, aangezien deze modellen manieren hebben waarop ze kunnen falen en worden uitgebuit die we nog maar net beginnen te verkennen.
In mijn bespreking tot nu toe heb ik alleen aan de oppervlakte van deze kwestie geraakt. Mijn analyse van vandaag gaat niet in op meer basale kwesties, zoals hoe we erop kunnen vertrouwen dat de leveranciers van deze ondoorzichtige modellen eerlijk zijn, en dat de inhoud van het model niet is gewijzigd: misschien door een aanval van binnenuit, of door kwaadwillende hackers van buitenaf. Elk van deze bedreigingen was ooit slechts theoretisch, en toch ik heb ze de afgelopen jaren allemaal in levende lijve zien plaatsvinden. Evenmin wordt overwogen hoe de reikwijdte van deze systemen door toekomstige regeringen zou kunnen worden vergroot, en hoe deze infrastructuur toekomstig misbruik waarschijnlijker zal maken.
Ter conclusie hoop ik dat de Commissie haar gehaaste schema zal heroverwegen en dit voorstel voldoende tijd zal geven om door wetenschappers en onderzoekers hier in Europa en de rest van de wereld te worden beoordeeld. We moeten proberen deze technische details te begrijpen als een voorwaarde voor het verplicht stellen van nieuwe technologieën, in plaats van te proberen ‘het vliegtuig te bouwen terwijl we erin vliegen’, wat dit voorstel in hoge mate zal aanmoedigen.
Bedankt voor uw tijd.